Galileo Galilei osserva il cielo dal suo cannocchiale
Riflettendo su quali sono i momenti in cui la scienza ha davvero fatto passi avanti, sono arrivata ad alcune considerazioni più specifiche sui Big data. Spesso le grandi rivoluzioni scientifiche sono precedute da una forte innovazione negli strumenti di misurazione. Fu così quando Galileo rivolse, con ‘curiosità informata’, il suo cannocchiale al cielo per l’osservazione degli astri.
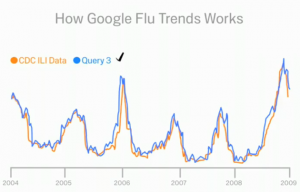
Nel 2009 destò grande stupore un lavoro pubblicato su Nature da parte di due ricercatori di Google che riuscirono a prevedere con altissima precisione il processo di diffusione dell’epidemia influenzale. Google flu trends fu il primo caso di utilizzo di Big data per fini scientifici ad aver avuto una risonanza mediatica planetaria. In effetti, Google era in grado di conoscere in tempo pressoché reale la diffusione dell’epidemia grazie alle parole chiave ricercate dagli utenti connesse con i sintomi e le cure dell’influenza. Diversamente, i centri nazionali preposti al monitoraggio dell’epidemia influenzale avevano bisogno almeno di una settimana per raccogliere e analizzare tutte le segnalazioni riportate. Google invece disponeva di dati sull’epidemia più tempestivi e, soprattutto, a costo zero.
Questa situazione è ormai sempre più frequente. Ogni giorno lasciamo come novelli pollicini infinite tracce digitali delle nostre attività quotidiane tramite browser, smartphone, pagamenti elettronici. L’enorme quantità di dati che sono oggi raccolti apre nuovi scenari dei quali è difficile dare una valutazione completa. Tralasciando aspetti che ci portano a dover ragionare con un nuovo approccio all’inferenza statistica quando si hanno svariate migliaia di dati da analizzare, è opportuno fare alcune riflessioni sulla natura dei Big data e sino a che punto questi siano una reale opportunità per il progresso della scienza.
Google flu trend
Non ne esiste una definizione universalmente condivisa, ma molto spesso ci si riferisce a essi indicando informazioni destrutturate disponibili in formati molto vari (numeri, testo, fotografie e video, reti sociali, ecc.), che vengono prodotte in grandi volumi (terabyte o petabyte), ad altissima velocità (gigabyte al secondo). Questa visione corrisponde alla definizione dei Big data in base alle tre V: varietà, volume, velocità. Quindi si differenziano molto chiaramente dai grandi dataset, semplicemente composti da molti milioni di righe, ma aventi una rigorosa struttura tabellare caso-variabile.
La maggior parte dei risultati che gli scienziati hanno pubblicato sino a oggi è stata supportata da rigorose analisi statistiche, con esperimenti molto spesso costruiti ad hoc e quindi con una rilevazione del dato finalizzata allo studio in corso, fondata su logiche di causa-effetto note o da validare. I nuovi approcci allo studio della realtà sono invece fondati su una logica diversa, la cosiddetta data-driven science, o scienza guidata dall’evidenza empirica.
Infatti, un approccio che intenda fondarsi sui Big data deve per lo più avvalersi di dati che non sono stati raccolti per finalità statistica o di ricerca, ma piuttosto di dati ‘trovati’ (in inglese found data). I Big data sono principalmente di natura amministrativa, raccolti per le più svariate ragioni, generalmente legati all’erogazione di un servizio all’utente. Se pensiamo a servizi web come per esempio quelli offerti da social media, appare immediatamente evidente l’immensità e la complessità dell’informazione disponibile.
Bisogna però porre attenzione a un particolare che attualmente viene spesso trascurato da molti entusiasti dei Big data: i found data contengono distorsioni sistematiche. Tutti i dati di Facebook e di Twitter non permettono di avere un’immagine completa della società italiana o mondiale: l’idea che ‘tanti dati’ equivalga a ‘tutti’ è un errore grossolano che può portare a fallire nella comprensione della società.
Infine, vale la pena qui sottolineare un ulteriore aspetto fondamentale che distingue le analisi sino a ora condotte attraverso l’uso dei Big data e l’analisi statistica tradizionale, ovvero la spiegazione del nesso di causalità. Le analisi di Big data, inclusi i Google flu trends, si riducono in generale a essere analisi di correlazione, cioè di concomitanza di fenomeni. Tuttavia l’analisi scientifica non può ignorare la comprensione dei nessi di causalità che da secoli sono alla base della nostra comprensione della realtà.
Filomena Maggino è Professore di Statistica Sociale presso l'Università di Roma La Sapienza.
FabbricaFuturo si trasferisce!
Abbiamo unito le nostre competenze e i nostri progetti editoriali con Parole di Management, dove troverai articoli, analisi e aggiornamenti sempre nuovi. Ti invitiamo a proseguire la lettura su www.paroledimanagement.it